Chapter 15 Advanced graphics
Much of this chapter is based strongly (for large parts identical) on the STAT444 course by Derek Sonderegger.
15.1 More general graphs: ggplot2
We have seen how to do simple graphs in a previous chapter. If we just want a “quick and dirty” view of a simple dataset (e.g. a residual plot) then this is often the quickest way to do things. A more general approach, and increasingly popular, is the ‘tidyverse’ which is a collection of modern packages that do some very useful things. One part of this tidyverse package is an advanced graphing library called ggplot2.
To install the package, remember we either use the “Tools-> Import Packages” menu and install tidyverse, or use the following command.
install.packages("tidyverse")We must load the package into memory using the library command every time:
library(tidyverse)To make the most of ggplot2 it is important to wrap your mind around “The Grammar of Graphics”. Briefly, the act of building a graph can be broken down into three steps.
Define what data set we are using.
What is the major relationship we wish to examine?
How should we present that relationship? These relationships can be presented in multiple ways, and the process of creating a good graph relies on building layers upon layers of information. For example, we might start with printing the raw data and then overlay a regression line over the top.
Next, note that ggplot2 is designed to act on data frames. However for any real data analysis project, the data will already be in a data frame and this is not an annoyance.
These notes describe creating simple graphs using ggplot2, but are not intended to be exhaustive. There are many places online to get help with ggplot2. One very nice resource is the website, http://www.cookbook-r.com/Graphs/, which gives much of the information available in the book R Graphics Cookbook which I highly recommend. Another is The R Graph Gallery which provides a good list of templates from which you can adapt to your problem.
One way that ggplot2 makes it easy to form very complicated graphs is that it provides a large number of basic building blocks that, when stacked upon each other, can produce extremely complicated graphs. A full list is available at http://docs.ggplot2.org/current/ but the following list gives some idea of different building blocks. These different geometries are different ways to display the relationship between variables and can be combined in many interesting ways.
| Geom | Description | Required Aesthetics |
|---|---|---|
geom_histogram |
A histogram | x |
geom_bar |
A barplot (y is number of rows) | x |
geom_col |
A barplot (y is given by a column) | x, y |
geom_density |
A density plot of data. (smoothed histogram) | x |
geom_boxplot |
Boxplots | x, y |
geom_line |
Draw a line (after sorting x-values) | x, y |
geom_path |
Draw a line (without sorting x-values) | x, y |
geom_point |
Draw points (for a scatterplot) | x, y |
geom_smooth |
Add a ribbon that summarizes a scatterplot | x, y |
geom_ribbon |
Enclose a region, and color the interior | ymin, ymax |
geom_errorbar |
Error bars | ymin, ymax |
geom_text |
Add text to a graph (with box) | x, y, label |
geom_label |
Add text to a graph (without box) | x, y, label |
geom_tile |
Create Heat map | x, y, fill |
A graph can be built up layer by layer, where:
- Each layer corresponds to a
geom, each of which requires a dataset and a mapping between an aesthetic and a column of the data set.- If you don’t specify either, then the layer inherits everything defined in the
ggplot()command. - You can have different datasets for each layer!
- If you don’t specify either, then the layer inherits everything defined in the
- Layers can be added with a
+, or you can define two plots and add them together (second one over-writes anything that conflicts).
15.1.1 Scatterplots
We’ll again use the iris dataset to demonstrate here.
ggplot( data=iris, aes(x=Sepal.Length, y=Petal.Length) ) +
geom_point( ) 
- The data set we wish to use is specified using
data=iris. - The relationship we want to explore is
x=Sepal.Lengthandy=Petal.Length. This means the x-axis will be the Sepal Length and the y-axis will be the Petal Length. - The way we want to display this relationship is through graphing 1 point for every observation (the
geom_pointgeometry).
We can define other attributes that might reflect other aspects of the data. For example, we might want the colour of the data point to change dynamically based on the species of iris.
ggplot( data=iris, aes(x=Sepal.Length, y=Petal.Length) ) +
geom_point( aes(colour=Species) )
The aes() command (short for aesthetic) inside the previous section of code is quite mysterious. The way to think about the aes() is that it gives you a way to define relationships that are data dependent. In the previous graph, the x-value and y-value for each point was defined dynamically by the data, as was the colour. If we just wanted all the data points to be coloured blue and larger, then the following code would do that
ggplot( data=iris, aes(x=Sepal.Length, y=Petal.Length) ) +
geom_point( colour='blue', size=4 )
The important part isn’t that colour and size were defined in the geom_point() but that they were defined outside of an aes() function!
- Anything set inside an
aes()command will be of the formattribute=Column_Nameand will change based on the data. - Anything set outside an
aes()command will be in the formattribute=valueand will be fixed.
15.1.2 Box Plots
Boxplots are a common way to show a categorical variable on the x-axis and continuous on the y-axis.
ggplot(iris, aes(x=Species, y=Petal.Length)) +
geom_boxplot() 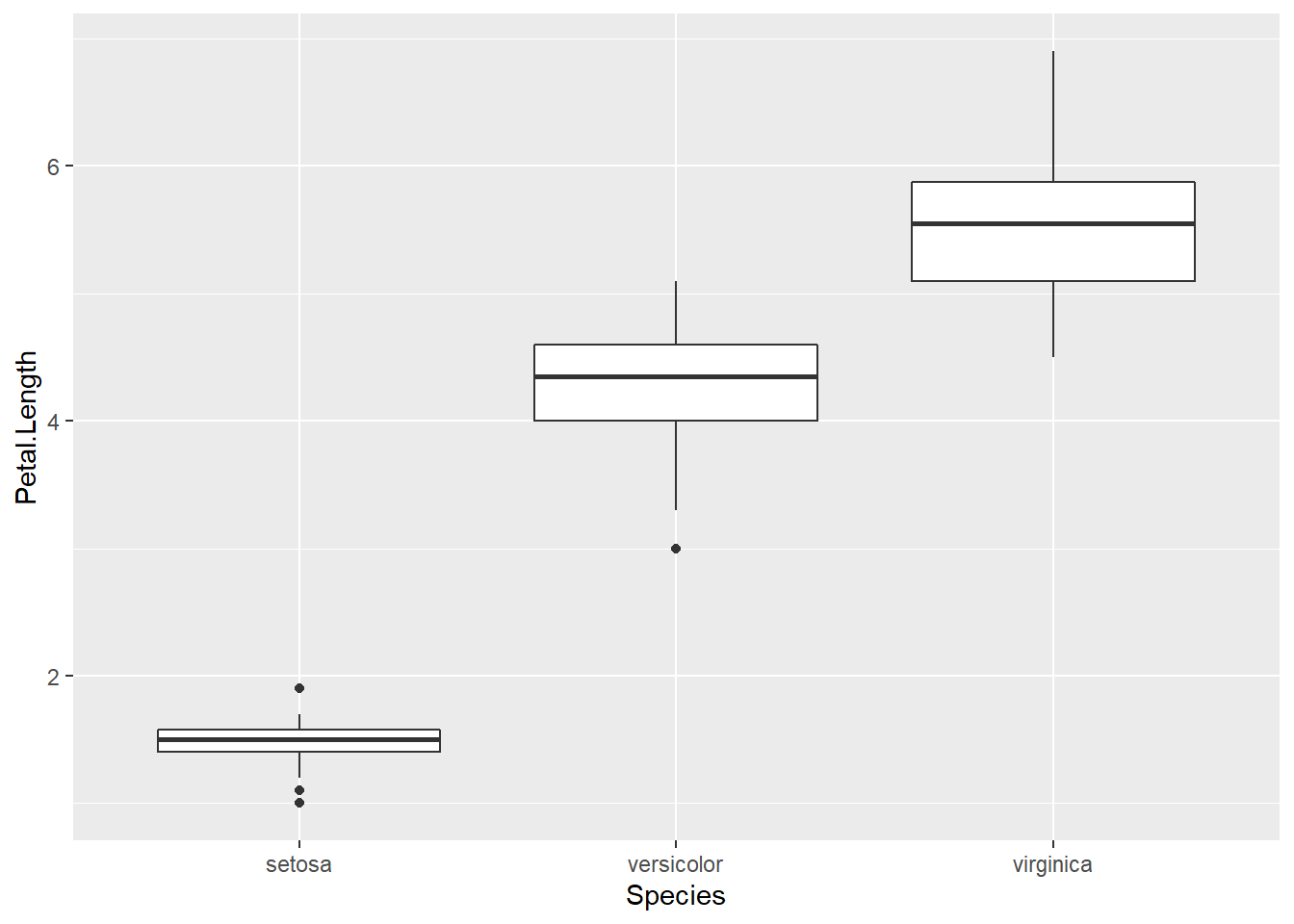
The boxes show the \(25^{th}\), \(50^{th}\), and \(75^{th}\) percentile and the lines coming off the box extend to the smallest and largest non-outlier observation.
15.2 Faceting
The goal with faceting is to make many panels of graphics where each panel represents the same relationship between variables, but something changes between each panel. For example using the iris dataset we could look at the relationship between Sepal.Length and Petal.Length either with all the data in one graph, or one panel per species.
library(ggplot2)
ggplot(iris, aes(x=Sepal.Length, y=Petal.Length)) +
geom_point() +
facet_grid( . ~ Species )
The line facet_grid( formula ) tells ggplot2 to make panels, and the formula tells how to orient the panels. In R, formulas are always interpreted in the order y ~ x. Because I want the species to change as we go across the page, but don’t have anything I want to change vertically we use . ~ Species to represent that. If we had wanted three graphs stacked then we could use Species ~ ..
For a second example, we look at a dataset that examines the amount a waiter was tipped by 244 parties. Covariates that were measured include the day of the week, size of the party, total amount of the bill, amount tipped, whether there were smokers in the group and the gender of the person paying the bill
library(reshape)## Warning: package 'reshape' was built under R version 4.1.3##
## Attaching package: 'reshape'## The following object is masked from 'package:dplyr':
##
## rename## The following objects are masked from 'package:tidyr':
##
## expand, smithsdata(tips, package='reshape')
head(tips)## total_bill tip sex smoker day time size
## 1 16.99 1.01 Female No Sun Dinner 2
## 2 10.34 1.66 Male No Sun Dinner 3
## 3 21.01 3.50 Male No Sun Dinner 3
## 4 23.68 3.31 Male No Sun Dinner 2
## 5 24.59 3.61 Female No Sun Dinner 4
## 6 25.29 4.71 Male No Sun Dinner 4It is easy to look at the relationship between the size of the bill and the percentage tipped.
ggplot(tips, aes(x = total_bill, y = tip / total_bill )) +
geom_point()
Next we ask if there is a difference in tipping percentage based on gender or day of the week by plotting this relationship for each combination of gender and day.
ggplot(tips, aes(x = total_bill, y = tip / total_bill, colour=time )) +
geom_point() +
facet_grid( sex ~ day )
# facet_grid( day ~ sex ) # changing orientation emphasizes certain comparisons!Sometimes we want multiple rows and columns of the facets, but there is only one categorical variable with many levels. In that case we use facet_wrap which takes a one-sided formula.
ggplot(tips, aes(x = total_bill, y = tip / total_bill )) +
geom_point() +
# facet_grid( . ~ day) # Four graphs in a row, Too Squished left/right!
facet_wrap( ~ day ) # spread graphs out both left/right and up/down.
Finally we can allow the x and y scales to vary between the panels by setting “free”, “free_x”, or “free_y”. In the following code, the y-axis scale changes between the gender groups.
ggplot(tips, aes(x = total_bill, y = tip / total_bill )) +
geom_point() +
facet_grid( sex ~ day, scales="free_y" )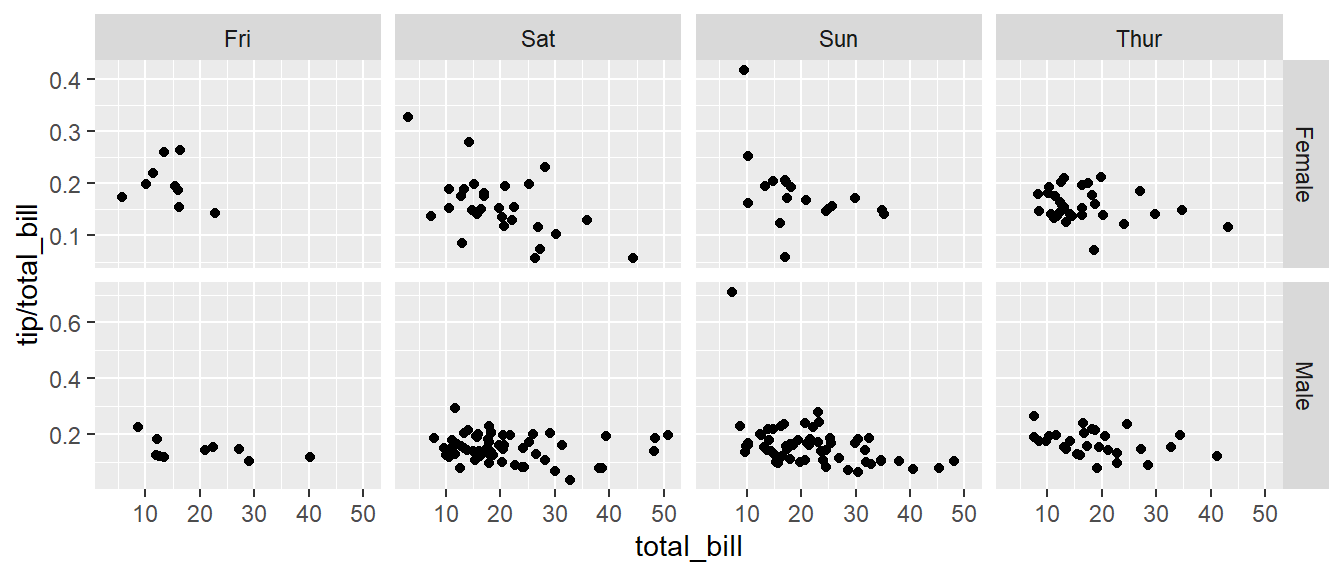
15.3 Annotation
15.3.1 Axis Labels and Titles
To make a graph more understandable, it is necessary to tweak the axis labels and add a main title and such. Here we’ll adjust labels in a graph, including the legend labels.
# Save the graph before I add more to it.
P <-
ggplot( data=iris, aes(x=Sepal.Length, y=Petal.Length, color=Species) ) +
geom_point( aes(colour=Species) ) +
labs( title='Sepal Length vs Petal Length' ) +
labs( x="Sepal Length (cm)", y="Petal Length (cm)" ) +
labs( color="Species Name") +
labs( caption = "Iris data from Edgar Anderson (1935)" )
# Print out the plot
P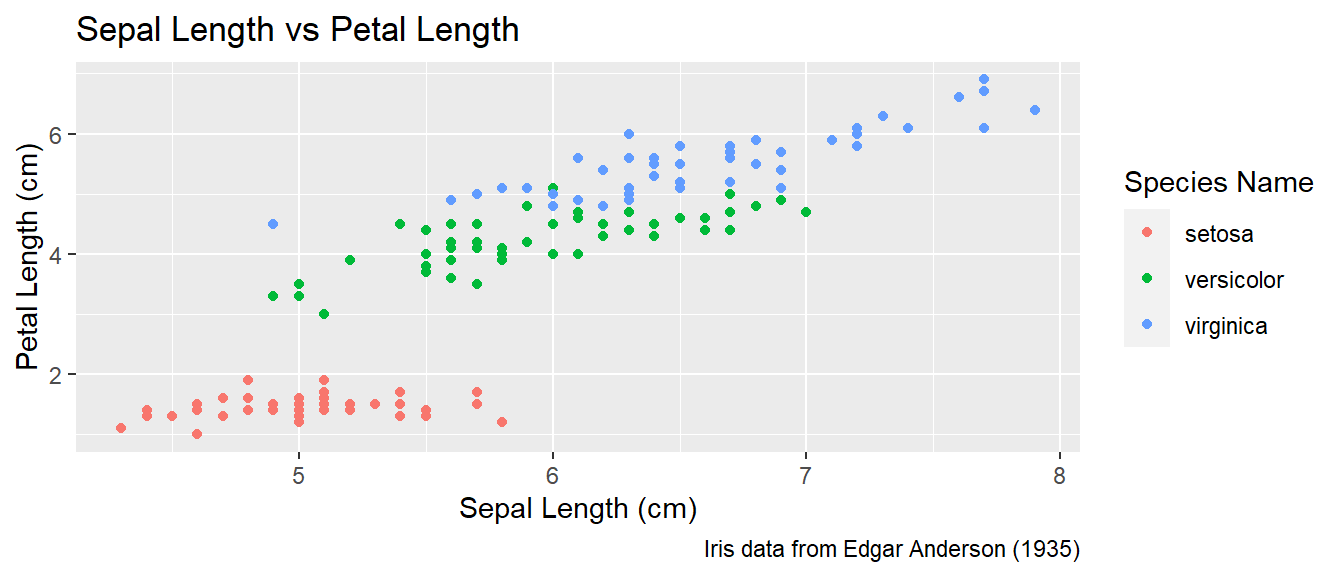
You could either call the labs() command repeatedly with each label, or you could provide multiple arguments to just one labs() call.
15.3.2 Text Labels
One way to improve the clarity of a graph is to remove the legend and label the points directly on the graph. For example, we could instead have the species names near the cloud of data points for the species.
Usually our annotations aren’t stored in the data.frame that contains our data of interest. So we need to either create a new (usually small) data.frame that contains all the information needed to create the annotation or we need to set the necessary information in-place. Either way, we need to specify the x and y coordinates, and the label to be printed, as well as any other attribute that is set in the global aes() command. That means if color has been set globally, the annotation layer also needs to address the color attribute.
15.3.2.1 Using a data.frame
To do this in ggplot, we need to make a data frame that has the columns Sepal.Length and Petal.Length so that we can specify where each label should go, as well as the label that we want to print. Also, because color is matched to the Species column, this small dataset should also have a the Species column.
This step always requires a bit of fussing with the graph because the text size and location should be chosen based on the size of the output graphic and if I rescale the image it often looks awkward. Typically I leave this step until the figure is being prepared for final publication.
# create another data frame that has the text labels I want to add to the graph.
annotation.data <- data.frame(
Sepal.Length = c(4.5, 6.5, 7.0), # Figured out the label location by eye.
Petal.Length = c(2.25, 3.75, 6.5), # If I rescale the graph, I would redo this step.
Species = c('setosa', 'versicolor', 'virginica'),
Text = c('SETOSA', 'VERSICOLOR', 'VIRGINICA')
)
# Use the previous plot I created, along with the
# aes() options already defined.
P +
geom_text( data=annotation.data, aes(label=Text), size=2.5) + # write the labels
theme( legend.position = 'none' ) # remove the legend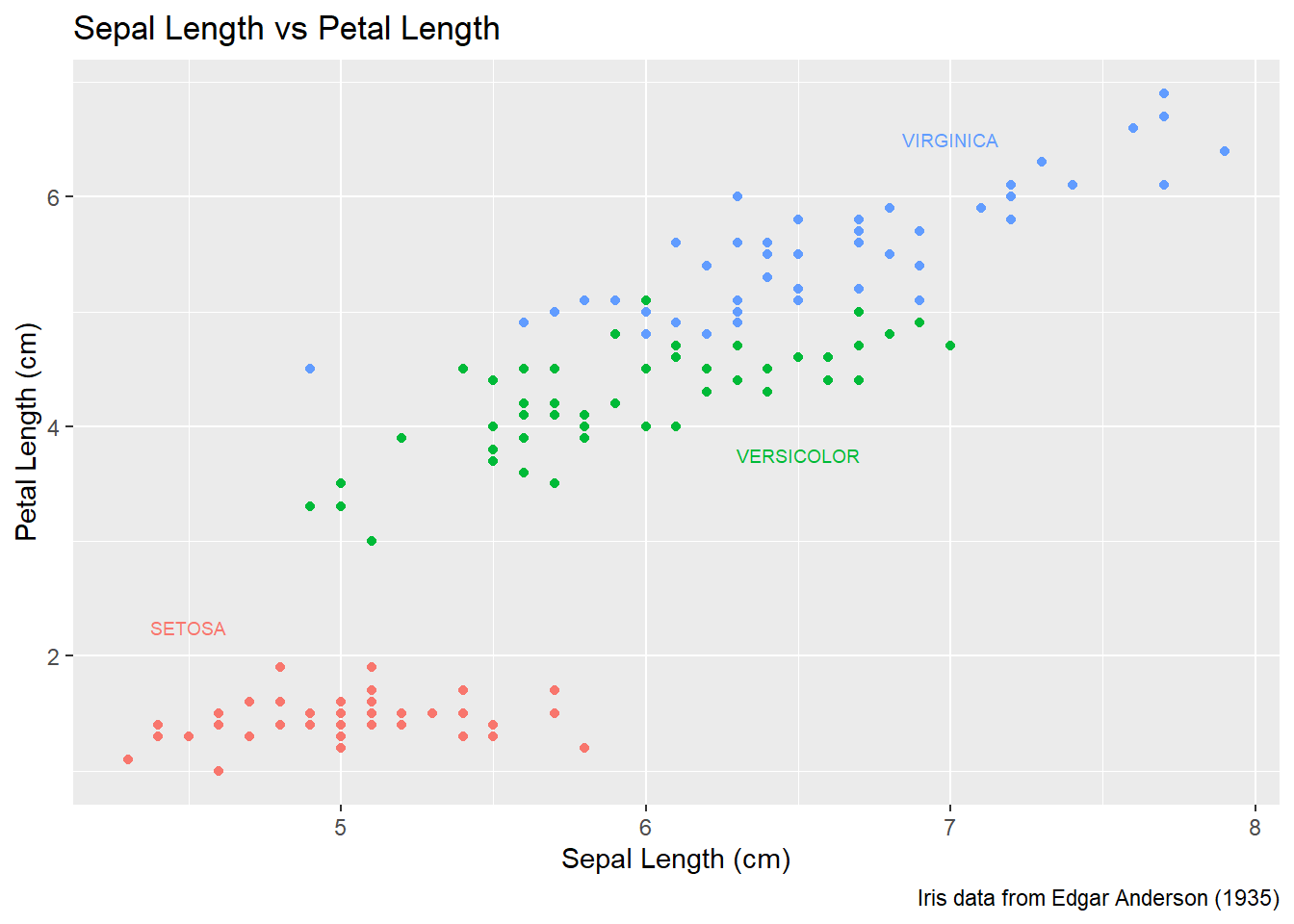
15.3.2.2 Setting attributes in-line
Instead of creating a new data frame, we could just add a new layer and just set all of the graph attributes manually. To do this, we have to have one layer for each text we want to add to the graph. The annotate function takes a geom layer type and the necessary inputs an allows us to avoid the annoyance of building a labels data frame.
P +
annotate('text', x=4.5, y=2.25, size=6, color='#F8766D', label='SETOSA' ) +
annotate('text', x=6.5, y=3.75, size=6, color='#00BA38', label='VERSICOLOR' ) +
annotate('text', x=7.0, y=6.50, size=6, color='#619CFF', label='VIRGINICA' ) +
theme(legend.position = 'none')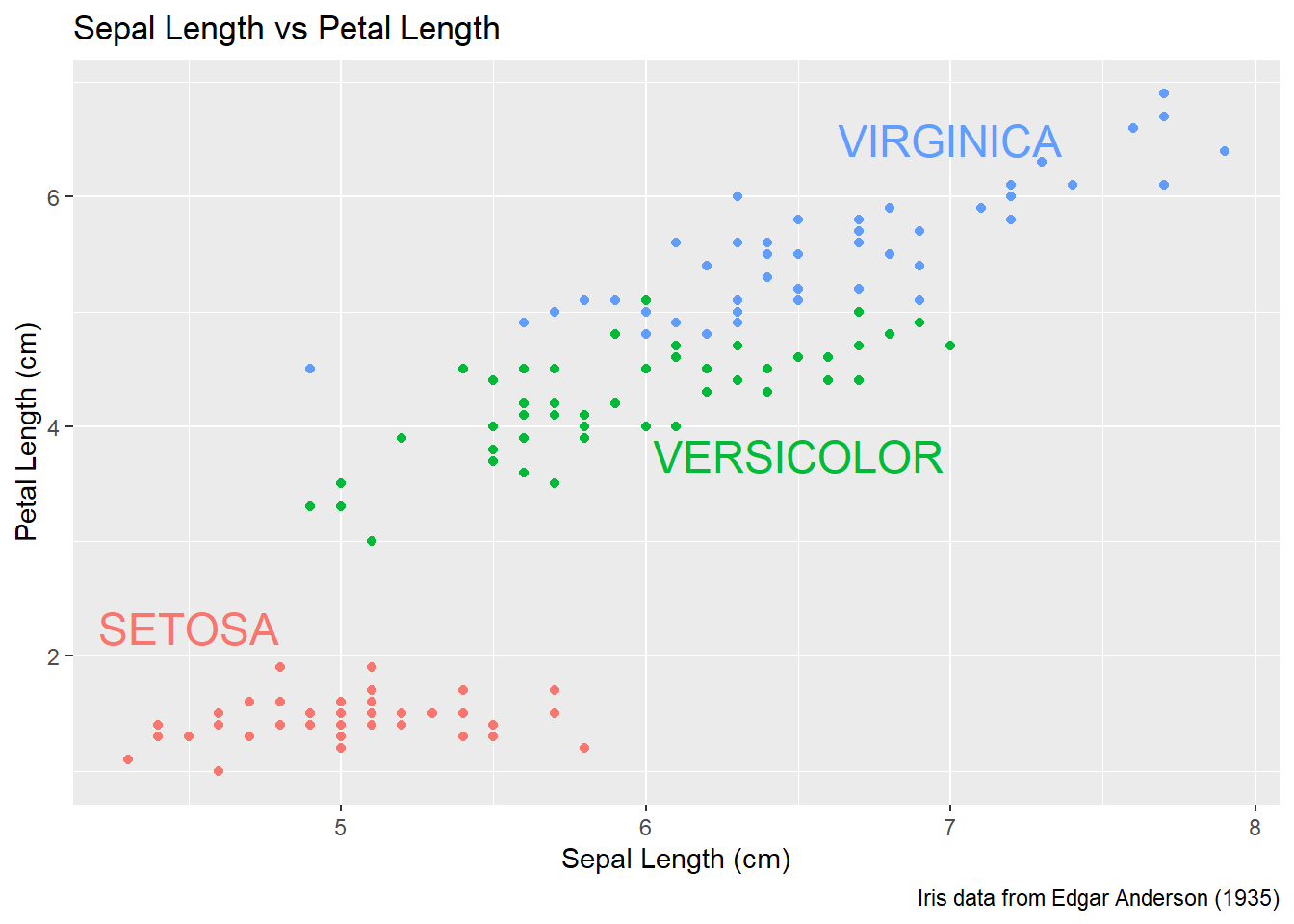
Finally there is a geom_label layer that draws a nice box around what you want to print.
P +
annotate('label', x=4.5, y=2.25, size=6, color='#F8766D', label='SETOSA' ) +
annotate('label', x=6.5, y=3.50, size=6, color='#00BA38', label='VERSICOLOR' ) +
annotate('label', x=7.0, y=6.75, size=6, color='#619CFF', label='VIRGINICA' ) +
theme(legend.position = 'none')
My recommendation is to just set the x, y, and label attributes manually inside an annotate() call if you have one or two annotations to print on the graph. If you have many annotations to print, the create a data frame that contains all of them and use data= argument in the geom to use that created annotation data set.
15.4 Exercises
Examine the dataset
trees, which should already be pre-loaded. Look at the help file using?treesfor more information about this data set. We wish to build a scatterplot that compares the height and girth of these cherry trees to the volume of lumber that was produced.- Create a graph using
ggplot2with Height on the x-axis, Volume on the y-axis, and Girth as the either the size of the data point or the color of the data point. Which do you think is a more intuitive representation? - Add appropriate labels for the main title and the x and y axes.
- The R-squared value for a regression through these points is 0.36 and the p-value for the statistical significance of height is 0.00038. Add text labels “R-squared = 0.36” and “p-value = 0.0004” somewhere on the graph.
- Create a graph using
Consider the following small dataset that represents the number of times per day a mother played “Ring around the Rosy” with her daughter relative to the number of days since she has learned this game. The column
yhatrepresents the best fitting line through the data, andlwranduprrepresent a 95% confidence interval for the predicted value on that day.Rosy <- data.frame( times = c(15, 11, 9, 12, 5, 2, 3), day = 1:7, yhat = c(14.36, 12.29, 10.21, 8.14, 6.07, 4.00, 1.93), lwr = c( 9.54, 8.5, 7.22, 5.47, 3.08, 0.22, -2.89), upr = c(19.18, 16.07, 13.2, 10.82, 9.06, 7.78, 6.75))Using
ggplot()andgeom_point(), create a scatterplot withdayalong the x-axis andtimesalong the y-axis.Add a line to the graph where the x-values are the
dayvalues but now the y-values are the predicted values which we’ve calledyhat. Notice that you have to set the aestheticy=timesfor the points andy=yhatfor the line. Because eachgeom_will accept anaes()command, you can specify theyattribute to be different for different layers of the graph.Add a ribbon that represents the confidence region of the regression line. The
geom_ribbon()function requires anx,ymin, andymaxcolumns to be defined. For examples of usinggeom_ribbon()see the online documentation: http://docs.ggplot2.org/current/geom_ribbon.html.What happened when you added the ribbon? Did some points get hidden? If so, why?
Reorder the statements that created the graph so that the ribbon is on the bottom and the data points are on top and the regression line is visible.
The color of the ribbon fill is ugly. Use Google to find a list of named colors available to
ggplot2. For example, I googled “ggplot2 named colors” and found the following link: http://sape.inf.usi.ch/quick-reference/ggplot2/colour. Choose a color for the fill that is pleasing to you.Add labels for the x-axis and y-axis that are appropriate along with a main title.
We’ll next make some density plots that relate several factors towards the birth weight of a child.
The
MASSpackage contains a dataset calledbirthwtwhich contains information about 189 babies and their mothers. In particular there are columns for the mother’s race and smoking status during the pregnancy. Load thebirthwtby either using thedata()command or loading theMASSlibrary.Read the help file for the dataset using
MASS::birthwt. The covariatesraceandsmokeare not stored in a user friendly manner. For example, smoking status is labeled using a 0 or a 1. Because it is not obvious which should represent that the mother smoked, we’ll add better labels to theraceandsmokevariables. For more information about dealing with factors and their levels, see theFactorschapter in these notes.library(tidyverse) data('birthwt', package='MASS') birthwt <- birthwt %>% mutate( race = factor(race, labels=c('White','Black','Other')), smoke = factor(smoke, labels=c('No Smoke', 'Smoke')))Graph a histogram of the birth weights
bwtusingggplot(birthwt, aes(x=bwt)) + geom_histogram().Make separate graphs that denote whether a mother smoked during pregnancy by appending
+ facet_grid()command to your original graphing command.Perhaps race matters in relation to smoking. Make our grid of graphs vary with smoking status changing vertically, and race changing horizontally (that is the formula in
facet_grid()should have smoking be the y variable and race as the x).Remove
racefrom the facet grid, (so go back to the graph you had in part d). I’d like to next add an estimated density line to the graphs, but to do that, I need to first change the y-axis to be density (instead of counts), which we do by usingaes(y=..density..)in theggplot()aesthetics command.Next we can add the estimated smooth density using the
geom_density()command.To really make this look nice, lets change the fill color of the histograms to be something less dark, lets use
fill='cornsilk'andcolor='grey60'. To play with different colors that have names, check out the following: http://www.stat.columbia.edu/~tzheng/files/Rcolor.pdf.Change the order in which the histogram and the density line are added to the plot. Does it matter and which do you prefer?
Finally consider if you should have the histograms side-by-side or one ontop of the other (i.e.
. ~ smokeorsmoke ~ .). Which do you think better displayes the decrease in mean birthweight and why?
Load the dataset
ChickWeight, which comes preloaded in R, and get the background on the dataset by reading the manual page?ChickWeight. Because these questions ask you to produce several graphs and evaluate which is better and why, please include each graph and response with each sub-question.Produce a separate scatter plot of weight vs age for each chick. Use color to distinguish the four different
Diettreatments.We could examine these data by producing a scatterplot for each diet. Most of the code below is readable, but if we don’t add the
groupaesthetic the lines would not connect the dots for each Chick but would instead connect the dots across different chicks.data(ChickWeight) ggplot(ChickWeight, aes(x=Time, y=weight, group=Chick )) + geom_point() + geom_line() + facet_grid( ~ Diet)
There is a spreadsheet with the football (soccer) results from the English Premiership 2019-2020 season available at this url. Because the
readrpackage doesn’t care whether a file is on your local computer or on the Internet, we’ll use this file.- Start the import wizard using: “File -> Import Dataset -> From Text (readr) …” and input the above web URL. Click the update button near the top to cause the wizard to preview the result.
- Save the generated code to your R Script file and show the first few rows using the
head()command. - The goals scored by the home side are in the ‘FTHG’ column. Calculate the mean number of goals for the home side.
- The result of the match (Home win, Draw, Away Win) are in the FTR column. Produce a crosstab using the table command to show the number of times each
HomeTeamachieved each result. Which team had the most draws in the season? - Produce bar charts showing the number of goals scored in each game (from the FTHG column)