OR-Notes are a series of introductory notes on topics that fall under the broad heading of the field of operations research (OR). They were originally used by me in an introductory OR course I give at Imperial College. They are now available for use by any students and teachers interested in OR subject to the following conditions.
A full list of the topics available in OR-Notes can be found here.
We examine one special kind of heuristic algorithm (called separable programming) that can be applied to certain types of nonlinear program's. (A heuristic algorithm is an algorithm that does not guarantee to find an optimal solution). We will illustrate separable programming by applying it to an example.
Consider the following NLP (nonlinear program)
maximise (x1)² + x2 subject to x1 + x2 <= 7 x1 <= 5 x2 <= 3 x1,x2 >= 0
Here we have only one nonlinear term (x1)² which is in the objective function which we are trying to maximise.
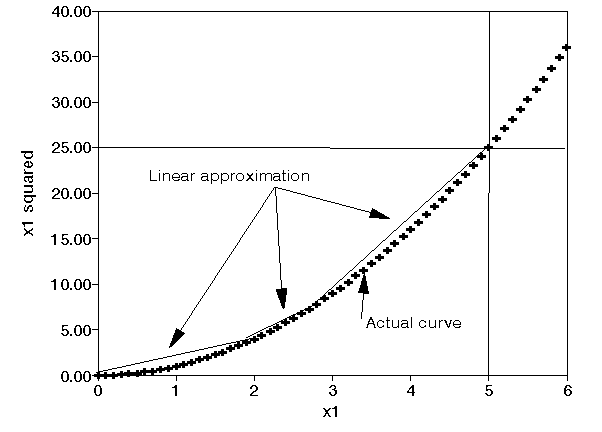
Consider the example NLP. Then the only nonlinear term is (x1)² and this nonlinear term involves just the single variable x1. We can deduce from the NLP that this single variable x1 must lie between zero and five (0 <= x1 <= 5). Hence (x1)² - the nonlinear term - must lie between zero and 25 and so we have the graph shown below.
Now one obvious way of solving (heuristically, that is approximately) the NLP is to approximate the nonlinear term (x1)² by some linear term since then we would then have an LP which we could solve to give an approximate (heuristic) solution to the original NLP. To see how this can be done choose some x1 values between 0 and 5 (e.g. x1 = 2, x1 = 3) and for these (two) x1 values define (three) straight lines to give a linear approximation of (x1)² in the range (0 <= x1 <= 5) we are interested in (as shown above).
Over the entire range 0 <= x1 <= 5 with the breakpoints defined at x1 = 0, x1 = 2, x1 = 3 and x1 = 5 (the two breakpoints we had before and the two endpoints) we claim that introducing variables A1, A2, A3, A4 (>= 0), 4 breakpoints in all so 4 variables, one associated with each breakpoint, i.e.
where
A1 + A2 + A3 + A4 = 1 (1)
and
x1 = A1(0) + A2(2) + A3(3) + A4(5) (2)
and
either only one Ai (some i <= 4) non-zero (3)
or only two adjacent Ai, Ai+1 (some i <= 3) non-zero (4)
enables us to approximate (x1)² by the linear expression
A1(0)² + A2(2)² + A3(3)² + A4(5)²
To see whether this claim is valid consider a few examples:
Then the appropriate Ai (i=1,2,3,4) values are clearly A1 = A2 = A4 = 0 and A3 = 1 with the approximation of (x1)² being given by
A1(0)² + A2(2)² + A3(3)² + A4(5)² = 0 + 0 + 1(3)² + 0 = 9
So in this case the approximation of (x1)² is exact.
Note here that the values of x1 and Ai (i=1,2,3,4) satisfy equations (1) and (2) and also that equation (3) is satisfied (but not equation (4)).
Note also that the Ai (i=1,2,3,4) values are uniquely defined (i.e. given x1 there is only one set of Ai values satisfying equations (1), (2), (3) and (4)).
Then the appropriate Ai (i=1,2,3,4) values can be deduced as follows (with the aid of the diagram above).
x1 = 2.25 lies between the second and third breakpoints so that A2 > 0 and A3 > 0 (implying A1 = A4 = 0). Also x1 = 2.25 lies 0.25 (A3) of the way from the second breakpoint to the third breakpoint. Hence A3 = 0.25, A2 = 1 - A3 = 0.75 and A1 = A4 = 0.
Note that equations (1) and (2) are satisfied as is equation (4) (but not equation (3)).
The approximation of (x1)² is given by
A1(0)² + A2(2)² + A3(3)² + A4(5)² = 0 + 0.75(2)² + 0.25(3)² + 0 = 5.25
Since x1 = 2.25 we have (x1)² = 5.0625 and so we have a reasonable approximation.
Then the appropriate Ai (i=1,2,3,4) values can be deduced as follows. x1 = 1.0 lies between the first and second breakpoints so that A1 >= 0 and A2 >= 0 (implying A3 = A4 = 0). Also x1 = 1.0 lies 0.5 (A2) of the way from the first breakpoint to the second breakpoint. Hence A2 = 0.5, A1 = 1 - A2 = 0.5 and A3 = A4 = 0.
Note again that equations (1) and (2) are satisfied as is equation (4) but not equation (3)).
The approximation of (x1)² is given by
A1(0)² + A2(2)² + A3(3)² + A4(5)² = 0 + 0.5(2)² + 0 + 0 = 2
Since x1 = 1.0 we have (x1)² = 1.0 so in this case the approximation is not very near to the true value. Plainly over the entire range for x1 (0 <= x1 <= 5) the approximation will be better at some points than at others.
Note here that it is important to ensure that the Ai (i=1,2,3,4) are such that either equation (3) or equation (4) is satisfied. If this is not the case then the approximation will be very far from the true value e.g. consider A1 = 0.55, A2 = A3 = 0 and A4 = 0.45 which do not satisfy either equation (3) or equation (4) but do satisfy equation (1) and equation (2) (with x1 = 2.25). Then with these Ai values (i=1,2,3,4) the approximation of (x1)² is given by
A1(0)² + A2(2)² + A3(3)² + A4(5)² = 0 + 0 + 0 + 0.45(5)² = 11.25
and compare this with the true value of 5.0625 and the previous approximation of 5.25 which we obtained with A1 = 0, A2 = 0.75, A3 = 0.25 and A4 = 0.
Hence we have shown how a nonlinear term like (x1)² can be replaced by a linear approximation. So consider the original NLP which we were trying to solve:
maximise (x1)² + x2 subject to x1 + x2 <= 7 x1 <= 5 x2 <= 3 x1,x2 >= 0
Introducing the linear approximation for (x1)² we get the LP:
maximise [A1(0)² + A2(2)² + A3(3)² + A4(5)²] + x2 subject to x1 + x2 <= 7 x1 <= 5 x2 <= 3 x1 = A1(0) + A2(2) + A3(3) + A4(5) A1 + A2+ A3 + A4 = 1 and either only one Ai (some i <= 4) non-zero or only two adjacent Ai, Ai+1 (some i <= 3) non-zero x1,x2>=0 and Ai>=0 i=1,2,3,4
This linear program is known as a linear approximation of the original NLP and can be solved heuristically by a variant of the simplex algorithm for LP.
Note here that we cannot solve this program optimally because of the either/or restriction relating to the Ai's. Whilst we could resort to mixed-integer programming to deal with these either/or restrictions this is seldom done, given the computational cost of solving an MIP optimally and given that we are approximating the original NLP by the MIP.
Note also that other linear approximations exist - for example we could have split the (x1)² nonlinear term differently by defining more breakpoints. This would lead to a more accurate linear approximation of (x1)² but at the expense of a larger program (more variables and more constraints) for the variant of the simplex algorithm to solve (i.e. we are trading off accuracy of approximation against computer time).
In fact it is usual to vary the spacing of the breakpoints so that we have more breakpoints in areas of the nonlinear function we think are of special interest (e.g. an area likely to be involved in the solution or an area where the value of the nonlinear function changes rapidly/significantly) and less breakpoints in other areas.
So far we have only considered nonlinear terms in the objective function but it is plain that we can also deal with nonlinear terms in the constraints in a similar manner to that used above.
Note here that the condition for us to be able to take any NLP and convert it into a new, linear, program is that each nonlinear term is a function of just a single variable and does not involve more than one variable (i.e. the NLP contains terms like (x1)² and (x2)³ but no terms like (x1)²(x2)5 which involve two variables).
Let us then summarise the steps we need to go through to generate a linear approximation of an NLP:
Step 1
Step 2
Step 3
Step 4
Step 5
Any NLP in which all the nonlinear terms are just functions of single variables is called a separable program and the above method of linear approximation is sometimes called separable programming.
This restriction on the nature of nonlinear terms would seem to limit the applicability of the method but in fact we can deal with some product terms, like x1x2, by using the fact that
Again we shall illustrate by an example.
maximise 2x1 + x2 subject to x1x2 <= 10 x1 <= 5 x2 <= 3 x1,x2 >= 0
We approach the problem via the five steps given above.
we need first to remove the x1x2 term (which is a function of two variables). Substituting from above for x1x2 the nonlinear constraint
x1x2 <= 10
becomes
[(x1 + x2)/2]2 - [(x1 - x2)/2]2 <= 10
We now introduce two new variables y1 and y2 where y1 = (x1 + x2)/2 and y2 = (x1 - x2)/2
Note here that y1 >= 0 but y2 can be positive or negative.
Then our nonlinear constraint becomes (y1)² - (y2)² <= 10 which is in a form we can deal with (e.g. consider the example given above where we approximated a square term).
establish a range for both y1 and y2. To establish a valid range for y1 we use the definition of y1 given above. Since y1 = (x1 + x2)/2 it is clear that
max value of y1 = ([max value of x1] + [max value of x2])/2
and
min value of y1 = ([min value of x1] + [min value of x2])/2
Now from the original NLP valid ranges for x1 and x2 are 0 <= x1 <= 5 and 0 <= x2 <= 3
Hence
max value of y1 = (5 + 3)/2 = 4
min value of y1 = (0 + 0)/2 = 0
so that a valid range for y1 is 0 <= y1 <= 4.
To establish a valid range for y2 we proceed in a similar manner. Since y2 = (x1 - x2)/2 it is clear that
max value of y2 = ([max value of x1] - [min value of x2])/2 and
min value of y2 = ([min value of x1] - [max value of x2])/2
So again using 0 <= x1 <= 5 and 0 <= x2 <= 3 we get that
max value of y2 = (5 - 0)/2 = 2.5
min value of y2 = (0 - 3)/2 = -1.5
Hence a valid range for y2 is -1.5 <= y2 <= 2.5.
introduce (arbitrary) breakpoints in the range of each variable, for each nonlinear term, as below:
Term Breakpoints Variables (y1)² y1 = 2, y1 = 3 Ai (i=1,2,3,4) (y2)² y2 = -1, y2 = 0, y2 = 2 Bi (i=1,2,3,4,5)
construct the linear approximation for each nonlinear term. Hence we have (y1)² approximated by the linear expression
A1(0)² + A2(2)² + A3(3)² + A4(4)²
where
y1 = A1(0) + A2(2) + A3(3) + A4(4)
A1 + A2 + A3 + A4 = 1
and either only one Ai (some i <= 4) non-zero or only two adjacent Ai, Ai+1 (some i <= 3) non-zero
(y2)² approximated by the linear expression
B1(-1.5)² + B2(-1)² + B3(0)² + B4(2)² + B5(2.5)²
where
y2 = B1(-1.5) + B2(-1) + B3(0) + B4(2) + B5(2.5)
B1 + B2 + B3 + B4 + B5 = 1
and either only one Bi (some i <= 5) non-zero or only two adjacent Bi, Bi+1 (some i <= 4) non-zero
the complete linear approximation of the original NLP is therefore given by:
maximise 2x1 + x2 subject to y1 = (x1 + x2)/2 y2 = (x1 - x2)/2 y1 = A1(0) + A2(2) + A3(3) + A4(4) y2= B1(-1.5) + B2(-1) + B3(0) + B4(2) + B5(2.5) A1 + A2 + A3 + A4 = 1 B1 + B2 + B3 + B4 + B5 = 1 [A1(0)² + A2(2)² + A3(3)² + A4(4)²] - [B1(-1.5)² + B2(-1)² + B3(0)² + B4(2)² + B5(2.5)²] <= 10 x1 <= 5 x2 <= 3 x1, x2, y1 >= 0 y2 can be positive or negative Ai >= 0 i=1,2,3,4 Bi >= 0 i=1,2,3,4,5 and either only one Ai (some i <= 4) non-zero or only two adjacent Ai, Ai+1 (some i <= 3) non-zero and either only one Bi (some i <= 5) non-zero or only two adjacent Bi, Bi+1 (some i <= 4) non-zero
Note here that the y variables can be eliminated from the above program
and so do not need to be explicitly considered.
Convert the following NLP into an appropriate linear approximation. Discuss the trade-off that occurs between the size of the resulting linear program and the accuracy of the approximation.
maximise (x1)5 + x2 subject to x1x2 <= 17 x1 <= 3 x2 <= 4 x1,x2 >= 0
We again approach the problem via the five steps given above.
in this NLP we have two nonlinear terms (x1)5 and x1x2. Both of these nonlinear terms are functions of single variables if we use the expansion of x1x2 that we gave above, namely:
x1x2 = [(x1 + x2)/2]2 - [(x1 - x2)/2]2
By putting
y1 = (x1 + x2)/2
and y2 = (x1 - x2)/2
where y1 >= 0 but y2 can be positive or negative we have that the nonlinear constraint
x1x2 <= 17
becomes (y1)² - (y2)² <= 17
which is in a form we can deal with as it contains two nonlinear terms, each a function of a single variable.
establish a valid range for each of the variables involved in a nonlinear term. We have three nonlinear terms (x1)5, (y1)² and (y2)² so we need to establish a valid range for x1, y1 and y2.
Looking back at the original NLP it is clear that a valid range for x1 is given by 0 <= x1 <= 3.
To establish a valid range for y1 we use the definition of y1 given above.
Since y1 = (x1 + x2)/2 it is clear that
max value of y1 = ([max value of x1] + [max value of x2])/2 and
min value of y1 = ([min value of x1] + [min value of x2])/2
Now from the original NLP valid ranges for x1 and x2 are given by 0 <= x1 <= 3 and 0 <= x2 <= 4 so that
max value of y1 = (3 + 4)/2 = 7/2
min value of y1 = (0 + 0)/2 = 0
Hence a valid range for y1 is 0 <= y1 <= 7/2.
We can establish a valid range for y2 in a similar manner.
Since y2 = (x1 - x2)/2 it is clear that
max value of y2 = ([max value of x1] - [min value of x2])/2 and
min value of y2 = ([min value of x1] - [max value of x2])/2
and again using 0 <= x1 <= 3 and 0 <= x2 <= 4
we get that
max value of y2 = (3 - 0)/2 = 3/2
min value of y2 = (0 - 4)/2 = -2
Hence a valid range for y2 is -2 <= y2 <= 3/2.
introduce (arbitrary) breakpoints in the range of each variable, for each nonlinear term, as below:
Term Breakpoints Variables (x1)5 x1 = 1, x1 = 2 Ai (i=1,2,3,4) (y1)² y1 = 1, y1 = 2 Bi (i=1,2,3,4) (y2)² y2 = -1, y2 = 0, y2 = 1 Ci (i=1,2,3,4,5)
construct the linear approximation for each nonlinear term. Hence we have (x1)5 approximated by the linear expression
A1(0)5 + A2(1)5 + A3(2)5 + A4(3)5
where
x1 = A1(0) + A2(1) + A3(2) + A4(3)
A1 + A2 + A3 + A4 = 1
and either only one Ai (some i <= 4) non-zero or only two adjacent Ai, Ai+1 (some i <= 3) non-zero
(y1)² approximated by the linear expression
B1(0)² + B2(1)² + B3(2)² + B4(7/2)²
where
y1 = B1(0) + B2(1) + B3(2) + B4(7/2)
B1 + B2 + B3 + B4 = 1
and either only one Bi (some i <= 4) non-zero or only two adjacent Bi, Bi+1 (some i <= 3) non-zero
(y2)² approximated by the linear expression
C1(-2)² + C2(-1)² + C3(0)² + C4(1)² + C5(3/2)²
where
y2 = C1(-2) + C2(-1) + C3(0) + C4(1) + C5(3/2)
C1 + C2 + C3 + C4 + C5 = 1
and either only one Ci (some i <= 5) non-zero or only two adjacent Ci, Ci+1 (some i <= 4) non-zero
the complete linear programming approximation of the original NLP is therefore given by
maximise [A1(0)5 + A2(1)5 + A3(2)5 +A4(3)5] + x2 subject to x1 = A1(0) + A2(1) + A3(2) + A4(3) y1 = (x1 + x2)/2 y2 = (x1 - x2)/2 y1 = B1(0) + B2(1) + B3(2) + B4(7/2) y2 =C1(-2) + C2(-1) + C3(0) + C4(1) + C5(3/2) A1 + A2 + A3 + A4 = 1 B1 + B2 + B3 + B4 = 1 C1 + C2 + C3 + C4 + C5 = 1 [B1(0)² + B2(1)² + B3(2)² + B4(7/2)²] - [C1(-2)² + C2(-1)² + C3(0)² + C4(1)² + C5(3/2)²] <= 17 x1 <= 3 x2 <= 4 All variables except y2 >= 0, y2 can be positive or negative and either only one Ai (some i <= 4) non-zero or only two adjacent Ai, Ai+1 (some i <= 3) non-zero and either only one Bi (some i <= 4) non-zero or only two adjacent Bi, Bi+1 (some i <= 3) non-zero and either only one Ci (some i <= 5) non-zero or only two adjacent Ci, Ci+1 (some i <= 4) non-zero
Note here that the y variables (y1,y2) can be eliminated from the above program and do not need to be explicitly considered.
The trade-off between the size of the linear program and the accuracy
of the approximation occurs because the more breakpoints we introduce for
any nonlinear term the better we approximate the nonlinear term, but the
larger the resulting linear program.
Convert the following NLP into an appropriate linear approximation.
maximise (x1)² + 2x2 + 3x3 subject to x2 + loge(x1) >= 2 x2x3 <= 20 2 <= x1 <= 3 x2 <= 5 x3 <= 20 x1,x2,x3 >= 0
We again approach the problem via the five steps given above.
in this NLP we have three nonlinear terms (x1)², loge(x1) and x2x3. All of these nonlinear terms are functions of single variables if we use the expansion of x2x3 that we gave before, namely:
x2x3 = [(x2 + x3)/2]2 - [(x2 - x3)/2]2
and putting
y1 = (x2 + x3)/2
y2 = (x2 - x3)/2
where y1 >= 0 but y2 could be positive or negative we have that the nonlinear constraint
x2x3 <= 20
becomes (y1)² - (y2)² <= 20
which is in a form we can deal with (as it contains two nonlinear terms, each a function of a single variable).
establish a valid range for each of the variables involved in a nonlinear term - these ranges are
Term Variable Range (x1² x1 2 <= x1 <= 3 loge(x1) x1 2 <= x1 <= 3 (y1)² y1 0 <= y1 <= 25/2 (y2)² y2 -10 <= y2 <= 5/2
introduce (arbitrary) breakpoints in the range of each variable, for each nonlinear term as below:
Term Breakpoints Variables (x1)² None Ai (i=1,2) loge(x1) x1 = 2.5 Bi (i=1,2,3) (y1)² y1 = 4, y1 = 8 Ci (i=1,2,3,4) (y2)² y2 = -2, y2 = 0, y2 = 1 Di (i=1,2,3,4,5)
Note here that we have different variables defined for the two nonlinear terms that involve x1. This is essential if (as above) we have chosen different breakpoints for the two nonlinear terms. If we have the same breakpoints then the variables should be the same.
construct the linear approximation for each nonlinear term. Hence we have (x1)² approximated by the linear expression
A1(2)² + A2(3)²
where
x1 = A1(2) + A2(3)
A1 + A2 = 1
loge(x1) approximated by the linear expression
B1(loge(2)) + B2(loge(2.5)) + B3(loge(3))
where
x1 = B1(2) + B2(2.5) + B3(3)
B1 + B2 + B3 = 1
and either only one Bi (some i <= 3) non-zero or only two adjacent Bi, Bi+1 (some i <= 2) non-zero
Note especially here how the loge(x1) term has been approximated.
(y1)² approximated by the linear expression
C1(0)² + C2(4)² + C3(8)² + C4(25/2)²
where
y1 = C1(0) + C2(4) + C3(8) + C4(25/2)
C1 + C2 + C3 + C4 = 1
and either only one Ci (some i <= 4) non-zero or only two adjacent Ci, Ci+1 (some i <= 3) non-zero
(y2)² approximated by the linear expression
D1(-10)² + D2(-2)² + D3(0)² + D4(1)² + D5(5/2)²
where
y2 = D1(-10) + D2(-2) + D3(0) + D4(1) + D5(5/2)
D1 + D2 + D3 + D4 + D5 = 1
and either only one Di (some i <= 5) non-zero or only two adjacent Di, Di+1 (some i <= 4) non-zero
the complete linear programming approximation of the original NLP is therefore given by
maximise [A1(2)² + A2(3)²] + 2x2 + 3x3 subject to x1 = A1(2) + A2(3) x1 = B1(2) + B2(2.5) + B3(3) y1 = (x2 + x3)/2 y2 = (x2 - x3)/2 y1 = C1(0) + C2(4) + C3(8)+ C4(25/2) y2 = D1(-10) + D2(-2) + D3(0) + D4(1) + D5(5/2) A1 + A2 = 1 B1 + B2 + B3 = 1 C1 + C2 + C3 + C4 = 1 D1 + D2 + D3 + D4 + D5 = 1 x2 + [B1(loge(2)) + B2(loge(2.5)) + B3(loge(3))] >= 2 [C1(0)² + C2(4)² + C3(8)² + C4(25/2)²] - [D1(-10)² + D2(-2)² + D3(0)² + D4(1)² + D5(5/2)²] <= 20 2 <= x1 <= 3 x2 <= 5 x3 <= 20 All variables except y2 >= 0, y2 can be positive or negative and either only one Bi (some i <= 3) non-zero or only two adjacent Bi, Bi+1 (some i <= 2) non-zero and either only one Ci (some i <= 4) non-zero or only two adjacent Ci, Ci+1 (some i <= 3) non-zero and either only one Di (some i <= 5) non-zero or only two adjacent Di, Di+1 (some i <= 4) non-zero
Note here that we have no either/or condition relating to Ai
since as we have only A1 and A2 the either/or condition
that we would normally include is automatically satisfied. Note also that
the y variables (y1,y2) can be eliminated from the
above program and so do not need to be explicitly considered.
Transform the nonlinear program shown below to a linear program.
maximise (x1)³ + x1 + x3 subject to x3 + loge(x1) <= 7 x1 + x2 + x3 <= 9 5 <= x1 <= 10 0 <= x2 <= 7 4 <= x3 <= 15
each nonlinear term is already a function of a single variable.
the ranges are
Nonlinear term Variable Range (x1)³ x1 5 <= x1 <= 10 loge(x1) x1 5 <= x1 <= 10
we now introduce (arbitrary) breakpoints in the range of each variable, for each nonlinear term, as below
Term Breakpoints Variables (x1)³ x1 = 7 Ai (i=1,2,3) loge(x1) x1 = 6, x1 = 8 Bi (i=1,2,3,4)
Note here that although both nonlinear terms are functions of the same variable (x1) we have different breakpoints and hence different variables (Ai and Bi).
Construct the linear approximation for each nonlinear term.
Hence we have (x1)³ approximated by the linear expression
A1(5)³ + A2(7)³ + A3(10)³
where
x1 = A1(5) + A2(7) + A3(10)
A1 + A2 + A3 = 1
and either only one Ai (some i <= 3) non-zero or only two adjacent Ai, Ai+1 (some i <= 2) non-zero
loge(x1) approximated by the linear expression
B1(loge(5)) + B2(loge(6)) + B3(loge(8)) + B4(loge(10))
where
x1 = B1(5) + B2(6) + B3(8) + B4(10)
B1 + B2 + B3 + B4 = 1
and either only one Bi (some i <= 4) non-zero or only two adjacent Bi, Bi+1 (some i <= 3) non-zero
the complete linear approximation of the original NLP is therefore given by
maximise A1(5)³ + A2(7)³ + A3(10)³ + x1 + x3 subject to x3 + B1(loge(5)) + B2(loge(6)) + B3(loge(8)) + B4(loge(10)) <= 7 x1 = A1(5) + A2(7) + A3(10) x1 = B1(5) + B2(6) + B3(8) + B4(10) A1 + A2 + A3 = 1 B1 + B2 + B3 + B4 = 1 x1 + x2 + x3 <= 9 5 <= x1 <= 10 0 <= x2 <= 7 4 <= x3 <= 15 all variables >= 0 and either only one Ai (some i <= 3) non-zero or only two adjacent Ai, Ai+1 (some i <= 2) non-zero and either only one Bi (some i <= 4) non-zero or only two adjacent Bi, Bi+1 (some i <= 3) non-zero