 Oyster
Simplifying citation search
Oyster
Simplifying citation search
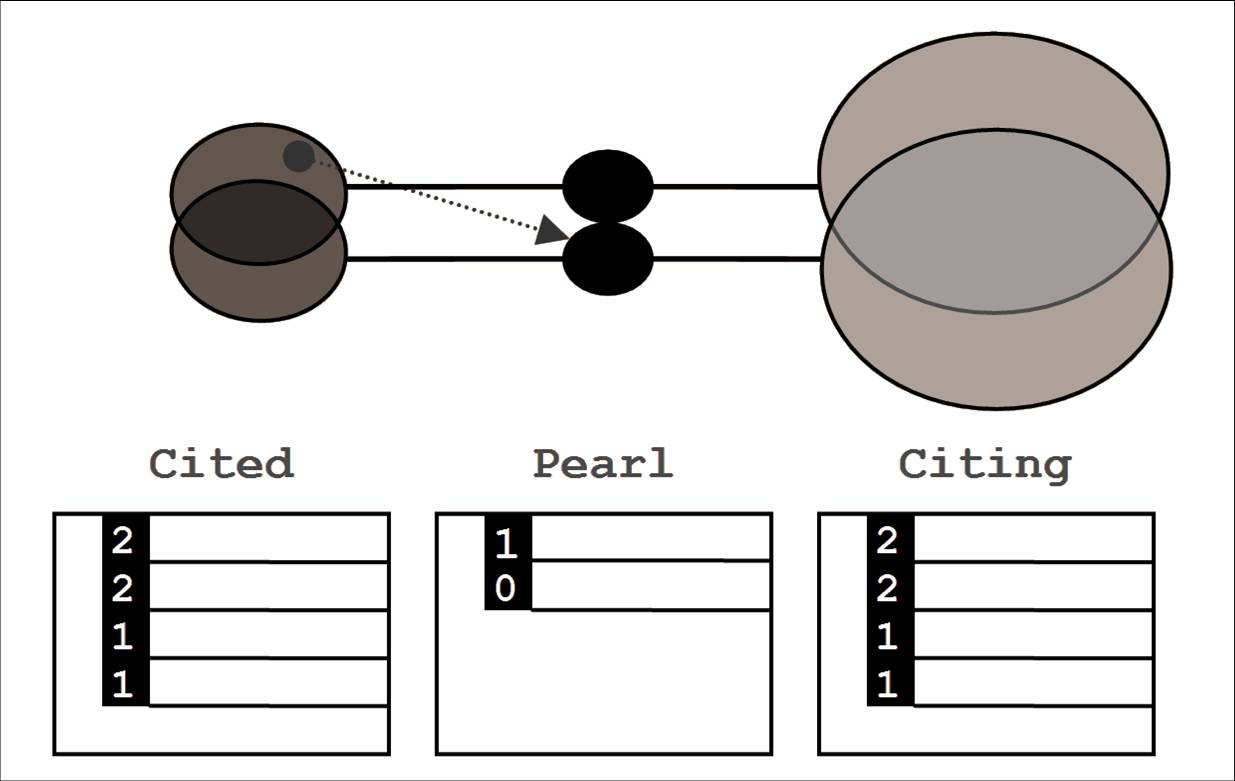
At the heart of Oyster is a simple three-list view which displays the aggregated sets of all articles that cite (right list) or are referenced by (left list) a set of one or more known relevant articles, called the 'pearl' (centre list). Articles are ranked according to the number of pearl articles that they have citation links to. As the pearl grows, articles that relate to more of the its articles get a higher score and 'bubble' to the top of the peripheral lists. This simple approach transforms the traditionally ardous task of citation searching into a fast moving, intuitive process where the salient intellectual space becomes more visible and focused with every interaction.
Oyster has two main task modes: cold start and hot start. Cold start is for researchers exploring a new topic area. The integrated fielded search interface allows you to begin your search from scratch using keywords, author names and date ranges. Alternatively, hot start is for researchers who want to check the completeness of an existing literature search/review. In this mode, a bibliography can be imported into the pearl list to kickstart the CCA process. Just save your bibliography in RIS export format (common to most reference managers) and load it into Oyster.
 |
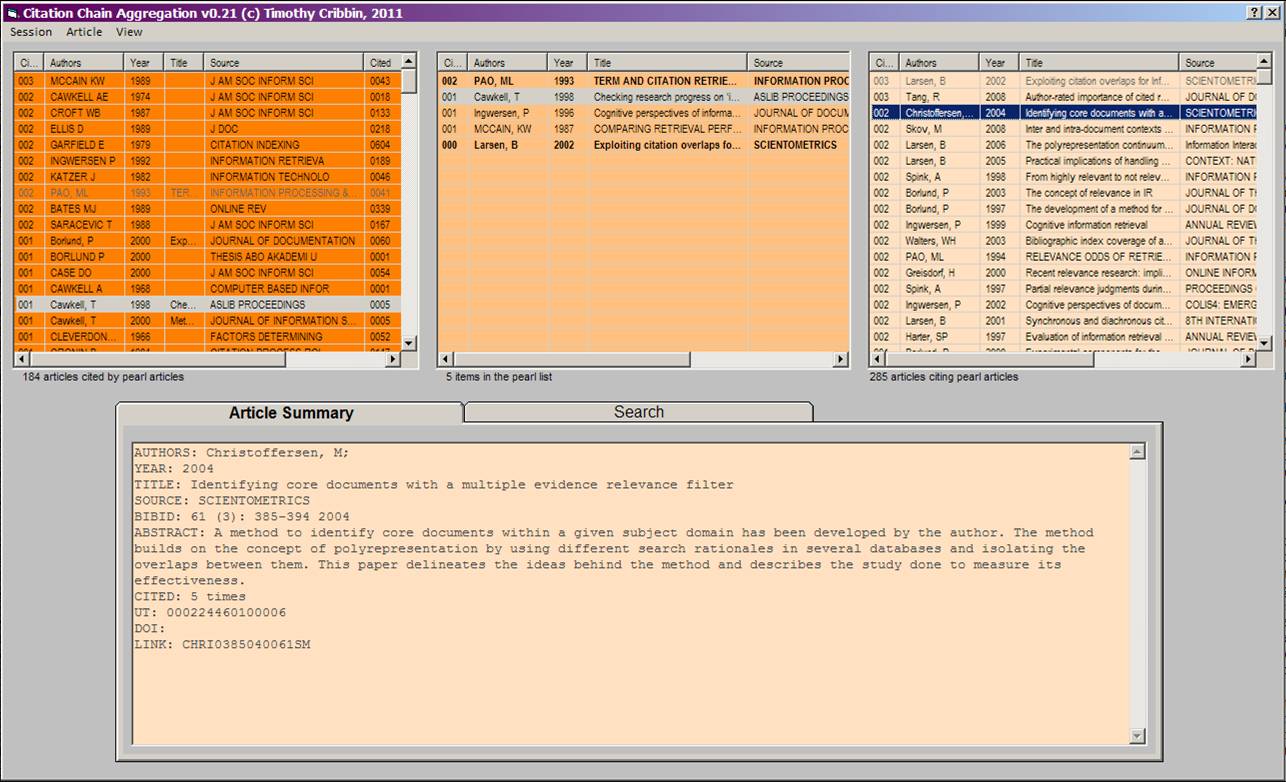 |
| CCA works by scoring citing and cited articles according to the number of pearl articles they are related to | The Oyster search interface implements the CCA concept using an interactive three-list view combined with a fielded search interface and bibliography import/export functions |
By default article records in the main list views are sorted by the pearl overlap score (i.e. number of pearl article relations). However, you can reorder items by any of the available fields/columns (e.g. citation count or source). It is easy to add article records to the pearl from the peripheral lists. Simply right click on the list item and a context menu appears with the option to 'add to pearl'. This menu also provides other functions like 'navigate to source' which will open up the article on the publisher's website. If you don't have a subscription to a resource, Oyster will attempt to locate an archived pre-/post-print instead.
Fielded searches can be conducted at any point during a session. Retrieved records can be sorted by relevance, citation count, year, title and source. As with the cited/citing lists, relevant articles can be added to the pearl by a simple right-click.
Once you are happy with your pearl list (or want to take a break) you can save your bibliography for future reference. This is conveniently saved in RIS export format, which is human readable and can be loaded back into Oyster (or your favourite reference manager) at a later stage.
Oyster is an experimental tool and, as such, is provided for free and 'as is'. Recent field trials with a sample of doctoral researchers have shown Oyster to be both useful and reliable. But don't take our word for it, download it now and give it a try. It's free - what do you have to lose?
If you choose to download and use Oyster, we would appreciate that you also take the time to email us with your feedback (good and bad). We have our own ideas for v2, but we are particularly interested to hear bug reports and feature wish-lists from all users of v1.
So have fun...
NEW Try the new Voyster prototype which augments the CCA model with a spatial-semantic (graphical) article map of the pearl citation space. Voyster depends on Graphvis (v2.28) for the visualisation layout. You can download the installer from here.
Note: Oyster is only as powerful as the data that drives it. Currently citation data is provided by Microsoft's excellent (and free) Academic Search API service. We express full acknowledgements and thanks to Microsoft research for providing this service, which currently indexes over 48 million articles across a wide range of academic subject areas (see Wikipedia entry). Note that from time to time, this service may suffer disruption. We have no control over the delivery of this service, so please don't email us to complain that it is slow or not working. Likewise, there is nothing we can do about errors or missing data that may occur in some records.
Reference:
Cribbin, T (2011). Citation Chain Aggregation: an interaction model to
support citation cycling.
In the proceedings of the 20th ACM International Conference on Information and
Knowledge Management (CIKM '11), Glasgow (October 24-28, 2011).
DOI
BURA